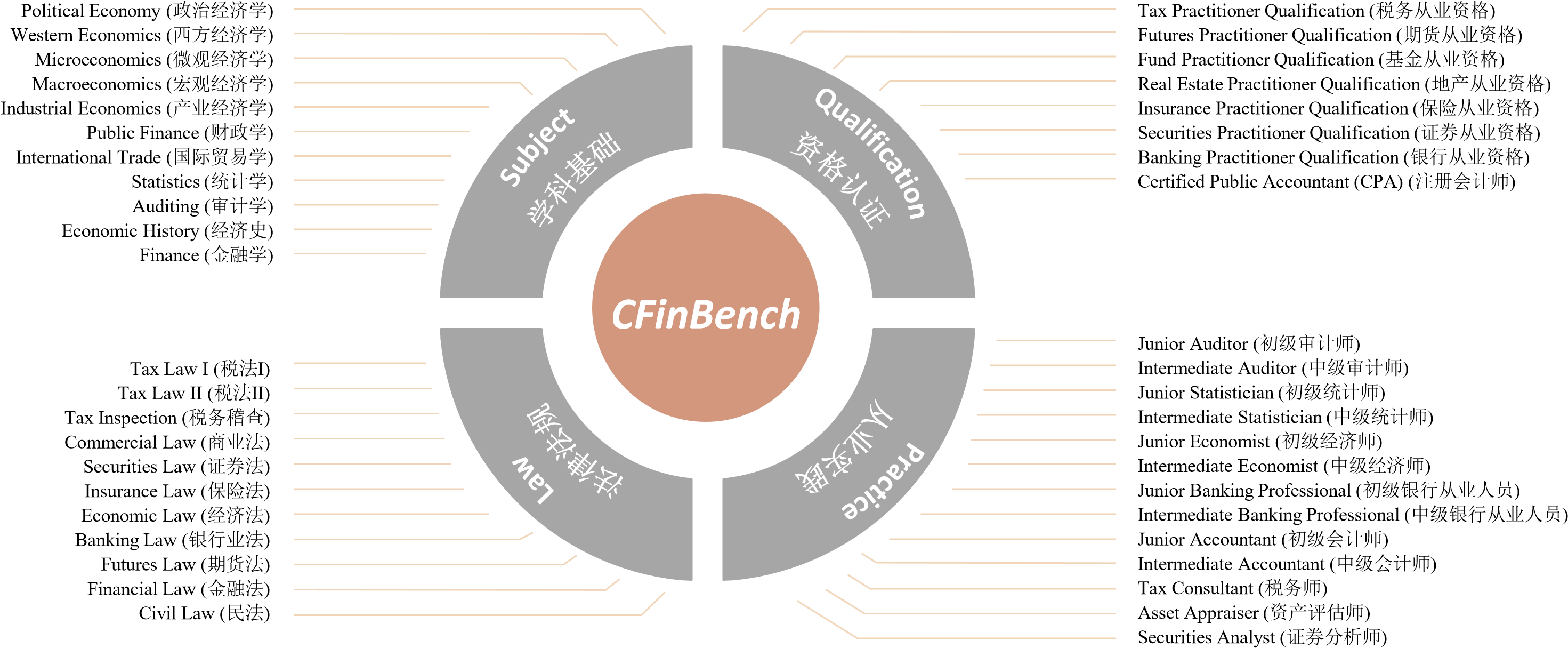
Large language models (LLMs) have achieved remarkable performance on various NLP tasks, yet their potential in more challenging and domain-specific task, such as finance, has not been fully explored. In this paper, we present CFinBench: a meticulously crafted, the most comprehensive evaluation benchmark to date, for assessing the financial knowledge of LLMs under Chinese context. In practice, to better align with the career trajectory of Chinese financial practitioners, we build a systematic evaluation from 4 first-level categories: (1) Financial Subject: whether LLMs can memorize the necessary basic knowledge of financial subjects, such as economics, statistics and auditing. (2) Financial Qualification: whether LLMs can obtain the needed financial qualified certifications, such as certified public accountant, securities qualification and banking qualification. (3) Financial Practice: whether LLMs can fulfill the practical financial jobs, such as tax consultant, junior accountant and securities analyst. (4) Financial Law: whether LLMs can meet the requirement of financial laws and regulations, such as tax law, insurance law and economic law. CFinBench comprises 99,100 questions spanning 43 second-level categories with 3 question types: single-choice, multiple-choice and judgment. We conduct extensive experiments of 50 representative LLMs with various model size on CFinBench. The results show that GPT4 and some Chinese-oriented models lead the benchmark, with the highest average accuracy being 60.16%, highlighting the challenge presented by CFinBench.





CFinBench is designed to evaluate the financial knowledge of large language models (LLMs) in Chinese contexts, focusing on advanced knowledge and complex reasoning skills. Inspired by previous works, it aims to challenge the capabilities of modern LLMs by using real-world examination questions across multiple dimensions. The questions are categorized into financial subjects, qualifications, practices, and laws, offering a comprehensive assessment framework.
The taxonomy of CFinBench includes four main categories: Financial Subject, Financial Qualification, Financial Practice, and Financial Law. Each category has subcategories that cover a wide range of financial topics and skills, from foundational knowledge to legal compliance.
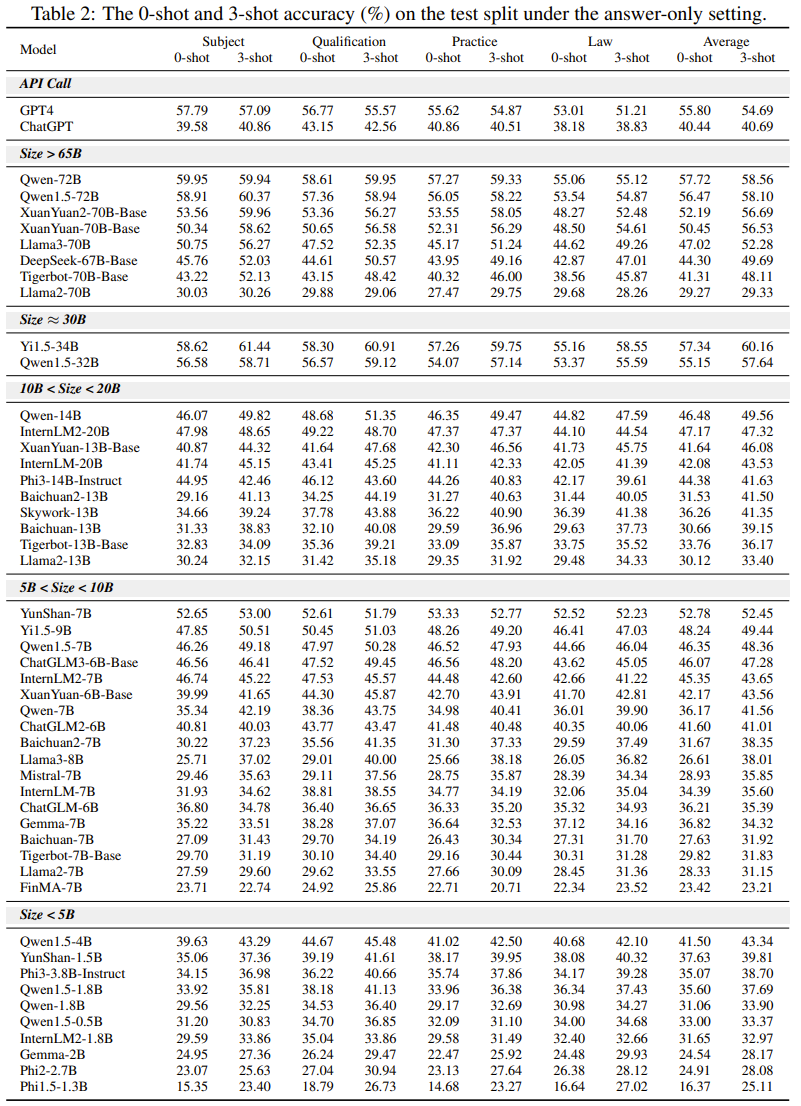
The figure above shows the 0-shot and 3-shot accuracy of various models on the test split under the answer-only setting (Table 2). Highlights include:
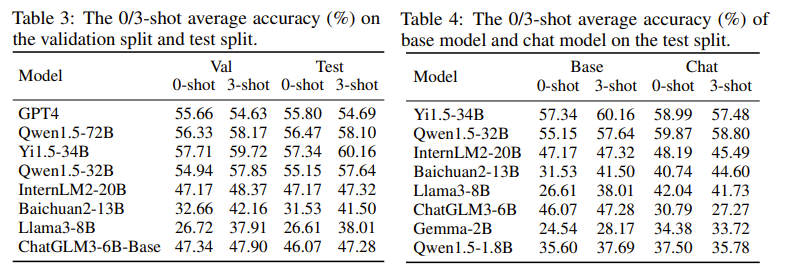
The figure above illustrates the 0/3-shot average accuracy on the validation and test splits (Table 3) and compares base and chat model accuracy on the test split (Table 4):